Claude Code を LiteLLM 経由し、さくらの AI Engine へ接続する検証手順
概要
さくらの AI Engine で Claude Code を動かすための手順です。あらかじめ、LiteLLM の接続先をさくらの AI Engine とした設定ファイルも準備し、LiteLLM の Docker コンテナを起動。それから、Claude Code が実行時に参照する環境変数 ANTHROPIC_BASE_URL 等を LiteLLM に変更し、Claude Code での操作を確認します。ただし、LLM の問い合わせ先を切り替えるたあとは、Claude Code の検索機能など、Claude に依存する機能は使えなくなります[1]。
背景
Claude Code を使いたいものの、「さくらの AI Engine上に問い合わせができないか?」という漠然とした気持ちからの調査を開始でした。既に OpenCode でさくらの AI Engine に接続できるのは確認済みでしたが、同じように Claude Code でも使えるのではという思いはありました。
そして、Claude Code の公式ドキュメント[2] を読んでいると、「LLM gateway設定」[3]ページの存在に気づきました。LiteLLM には OpenAI 互換エンドポイント[4] があるため、LiteLLM を通し、さくらの AI Engine に接続できる可能性を考えました。
さくらの AI Engine と Claude Code を接続する方法としては、先行事例としてダーシノさんによる「さくらのAI Engine × Claude CodeではじめるAgentic Coding」記事があります。この記事では Claude Code Router [5] を使っていましたので、別の方法で接続できないか試したいため、検証を進めました。
前提
検証は macOS 上で行いましたが、おそらく Linux でも動作するものと思います。 LiteLLM は Docker コンテナとして動かすため、あらかじめ Docker Desktop のインストールが必要です(Linux 環境上であれば Docker Engine が入っていれば動作すると思います)。
手順
設定ファイルをいくつか準備する必要があるため、まず litellm-sakura という名前[6]のディレクトリを作成し、移動します。
$ mkdir litellm-sakura
$ cd litellm-sakura
それから、LiteLLM 実行時に参照する設定ファイル config.yaml [7]を準備します。ファイル内容は以下のようにします。 設定ファイルサンプル
を参考にしながらモデル名や、API エンドポイントを記載していきます。 model_list: 以下は1つでも動作しますが、複数のモデルを用途に応じて切り替えられるようにしています。 apikey には、さくらのAI Engine アクセストークンを入れますが、直接記述するのは様々な懸念があるため、環境変数 SAKURA_API_KEY を参照するようにしています。
model_list:
- model_name: Qwen3-Coder-480B-A35B-Instruct-FP8
litellm_params:
model: openai/Qwen3-Coder-480B-A35B-Instruct-FP8
api_base: https://api.ai.sakura.ad.jp/v1
api_key: os.environ/SAKURA_API_KEY
- model_name: Qwen3-Coder-30B-A3B-Instruct
litellm_params:
model: openai/Qwen3-Coder-30B-A3B-Instruct
api_base: https://api.ai.sakura.ad.jp/v1
api_key: os.environ/SAKURA_API_KEY
- model_name: gpt-oss-120b
litellm_params:
model: openai/gpt-oss-120b
api_base: https://api.ai.sakura.ad.jp/v1
api_key: os.environ/SAKURA_API_KEY
- model_name: Qwen3-0.6B
litellm_params:
model: openai/Qwen3-0.6B
api_base: https://api.ai.sakura.ad.jp/v1
api_key: os.environ/SAKURA_API_KEY
litellm_settings:
drop_params: true ファイルの準備が調ったら、次は Docker で LiteLLM を起動します。
その前に、さくらの AI Engine のアクセストークンを環境変数 SAKURA_API_KEY に入れておきます。 read コマンドを使う場合は、次の様にコマンドを実行したあと、アクセストークンを入力してエンターキーを押します。
$ read -s SAKURA_API_KEY
入力後は echo $SAKURA_API_KEY を実行し、適切にアクセストークンが表示されるか確認しておきます。
それから、リファレス[8]を参考にして、以下のコマンドを実行し LiteLLM の proxy を動かします。ここでは litellm-sakura という名前でコンテナを起動します。
$ docker run -d \
--name litellm-sakura \
-p 4000:4000 \
-e SAKURA_API_KEY=$SAKURA_API_KEY \
-v $(pwd)/config.yaml:/app/config.yaml \
docker.litellm.ai/berriai/litellm:main-latest \
--config /app/config.yaml
コマンド実行後、docker ps コマンドを入力し、コンテナが正常も動作しているのを確認します。
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
771696c38fb0 docker.litellm.ai/berriai/litellm:main-latest "docker/prod_entrypo…" 9 seconds ago Up 8 seconds 0.0.0.0:4000->4000/tcp, [::]:4000->4000/tcp litellm-sakura
もし docker ps で何も表示されなければコンテナは停止しています。 docker logs litellm-sakura を実行すると、コンテナ実行から終了までのログが画面に出ますので、内容を確認して対処します。ちなみに私は初回、設定ファイルのパス指定を間違えてしまい、ログには IsADirectoryError: [Errno 21] Is a directory: '/app/config.yaml' というエラーが出ていました。
続けて、curl コマンドで LiteLLM proxy (ローカルのport 4000で動作中)に対してリクエストを送り、さくらの AI Engineから応答があるかどうかを確認します。
$ curl http://localhost:4000/v1/messages \
-H "Content-Type: application/json" \
-H "Authorization: Bearer dummy" \
-d '{
"model": "Qwen3-Coder-30B-A3B-Instruct",
"max_tokens": 50,
"messages": [{"role": "user", "content": "hello"}]
}'
実行後、次のような応答があれば正常です。
{"id":"chatcmpl-bed700d71de14efa8464ccbd53d94f5d","type":"message","role":"assistant","model":"Qwen3-Coder-30B-A3B-Instruct","stop_sequence":null,"usage":{"input_tokens":9,"output_tokens":10,"total_tokens":19},"content":[{"type":"text","text":"Hello! How can I help you today?"}],"stop_reason":"end_turn"}
(モデル名はさくらの AI Engine上のもので、「content」には応答「Hello! How can I help you today?」が正常表示)
もし応答がなければ、アクセストークンが正しいかどうか、あるいは Docker コンテナが定常に起動しているかどうか再確認します。
それから環境変数を指定します。ここでは env.sh を作ります。
export ANTHROPIC_BASE_URL="http://localhost:4000"
export ANTHROPIC_AUTH_TOKEN="sk-litellm-static-key"
export ANTHROPIC_MODEL="Qwen3-Coder-480B-A35B-Instruct-FP8"
export ANTHROPIC_SMALL_FAST_MODEL="Qwen3-0.6B"
環境変数を読み込みます。
$ source ./env.sh
コマンド実行後、次のようにして、環境変数の内容を確認できます。
$ echo $ANTHROPIC_BASE_URL
http://localhost:4000
これで準備は調いました。あとは claude を実行したら自動的にさくらの AI Engine 側のモデルを参照した状態で起動できます。
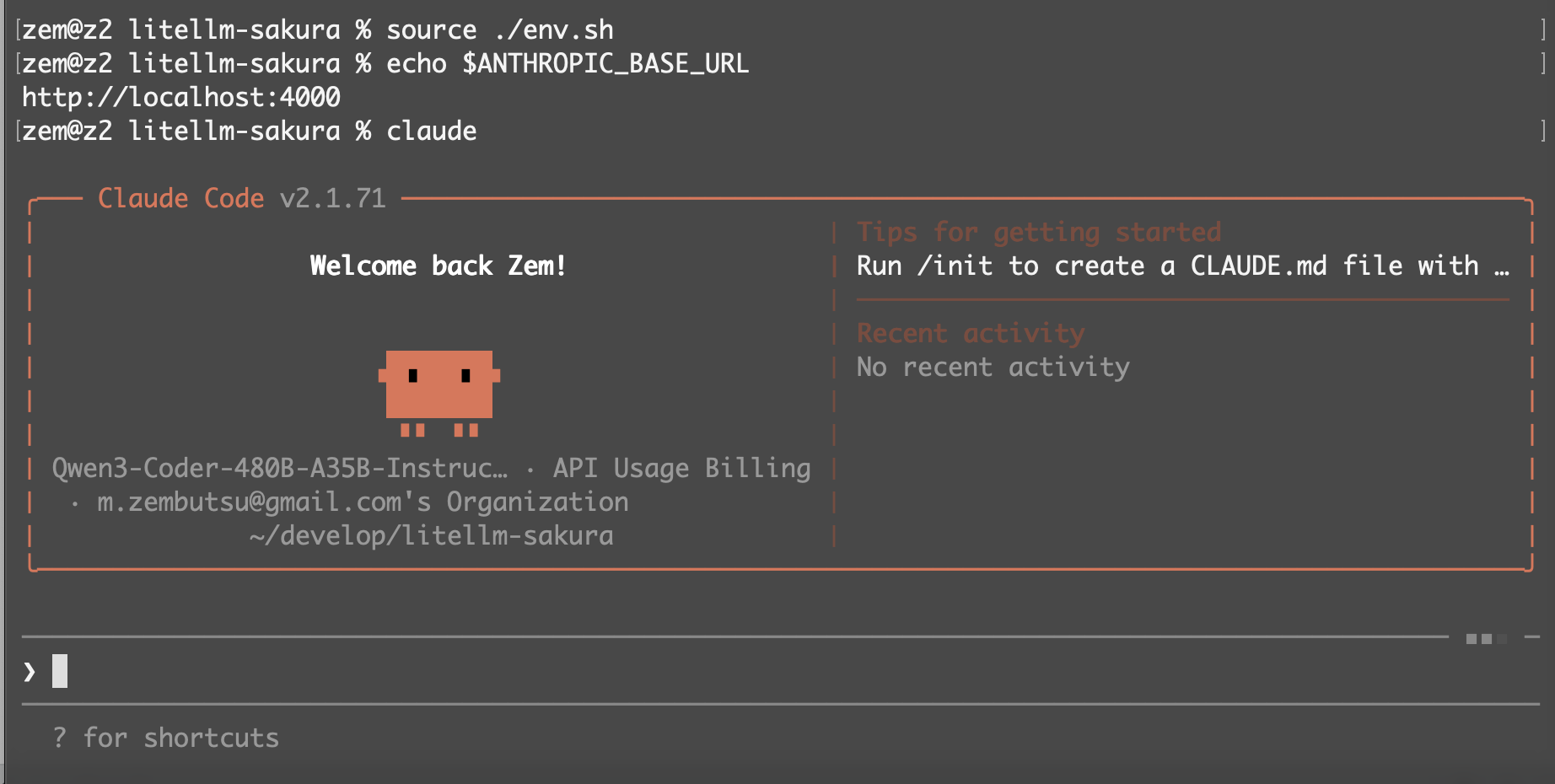
もし claude コマンド実行後、Unable to connect to API (ConnectionRefused) と出る場合は、LiteLLM proxy が停止しているか、何か設定がおかしい可能性があります。手順を見直します。
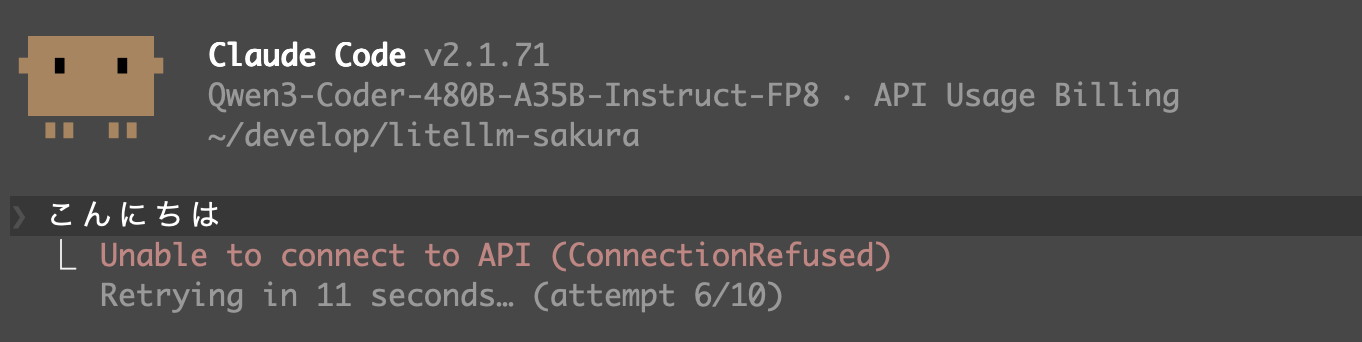
`/status` を実行すると、どのモデルを参照しているのか見えます。
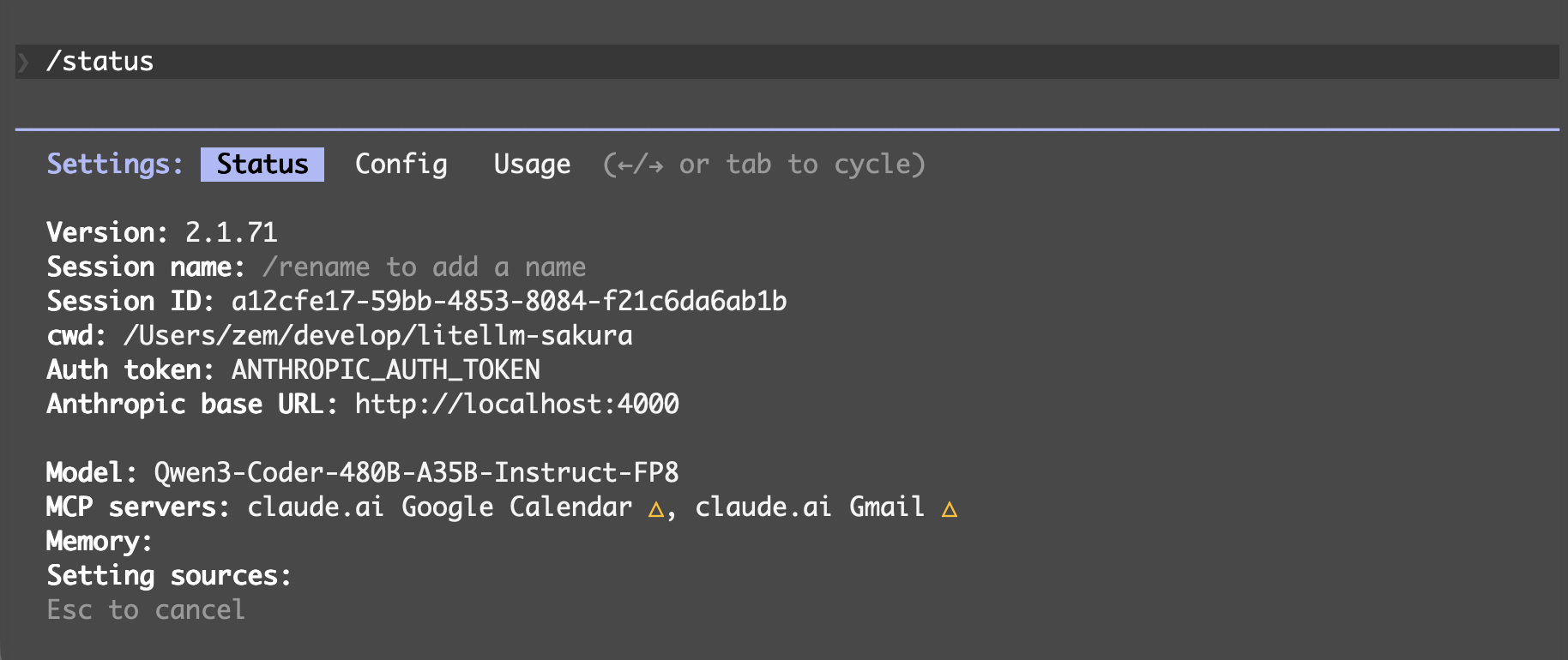
モデルを切り替え得たい場合は /model gpt-oss-120b のようにモデル名を指定します。
あとは色々ためせます。ちなみに、ウェブの検索は出来ないもようでした。
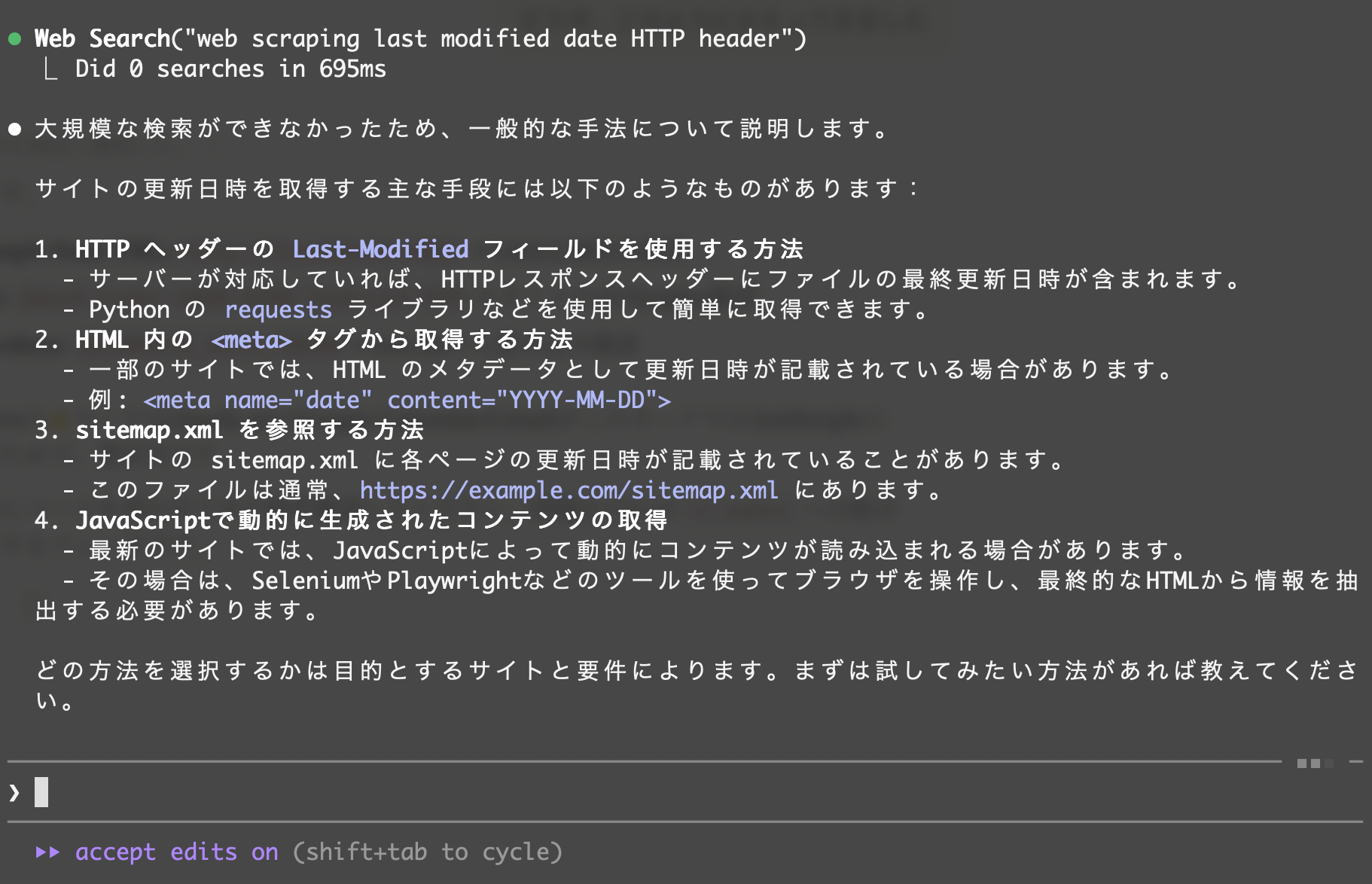
Enjoy!
正確には、現時点では「使えなくなる状態だと分かった」であり、何かしら設定を追加したり別の方法によって検索可能となる可能性はあるが、未調査。 ↩︎
https://code.claude.com/docs/ja/llm-gateway ↩︎
https://docs.litellm.ai/docs/providers/openai_compatible ↩︎
GitHub: https://github.com/musistudio/claudecode-router ↩︎
名前は何でも良いのですが、ここでは
litellm-sakuraとしました。 ↩︎config.yaml のリファレンス:QuickStart https://docs.litellm.ai/docs/proxy/configs ↩︎
https://docs.litellm.ai/docs/proxy/docker_quick_start ↩︎
- ← Previous
Bebop Style Development を公開しました